









dbt Core Orchestration with Amazon Athena and Dagster: A Complete Guide to Scalable Data Workflows
Reading time: 8 minutes
Data transformation can be difficult, due to issues such as raw SQL queries that are difficult to share or reuse, and untested queries that can fail in pipelines. dbt Core (Data Build Tool) offers a solution by providing a framework for transforming raw data into clean, usable datasets. Using SQL, dbt helps data engineers efficiently create, test, and document data transformation workflows, solving many common data transformation problems.
In this article, we’ll explore how to effectively use dbt for data transformation, then dive into the benefits of integrating it with Amazon Athena and how to orchestrate these processes using Dagster.
Section 1: The power of dbt Core in data transformation
dbt (data build tool) has revolutionized the way data teams manage their transformation workflows. Imagine you are working with a customer table containing data from various sources. The goal is to clean this data, ensuring it is accurate and ready for analysis.
dbt core provides a structured way to handle this, transform raw SQL queries into reusable templatesenabling efficient data testing and management of incremental updates.
Additionally, DBT’s main offerings full data traceabilityallowing you to follow the flow of data through various transformations and understand how each piece of data is derived, ensuring transparency and traceability of your workflows.
Use dbt for data transformation
Let’s start with a simple transformation. Let’s say we need to create a clear view of our customer data. With dbt you can write an SQL model like this:
{{ config(
materialized='view'
) }}
SELECT
client_id,
client_name,
date
FROM
{{ ref('client_data') }}
WHERE
client_id is not null
and client_name is not null
and date is not nullIn this example, we create a view (materialized=’view’) that selects non-zero customer data from a client_data source table. The SQL here is standard, making it easy for anyone familiar with SQL to understand and modify.
Ensuring data quality with testing
Data quality is crucial. dbt core allows you to set tests to ensure your data meets specific criteria. For example, we want to ensure that client_id is unique and client_name is not null, using dbt native data tests.
Additionally, we may have a custom requirement that customer names must contain only letters and spaces.
Here’s how to achieve it use macros and dbt tests.
First, define a custom test macro:
{% test name_format(model, column_name) %}
SELECT *
FROM {{ model }}
WHERE NOT REGEXP_LIKE({{ column_name }}, '^[A-Za-z\s]+$')
{% endtest %}Then apply this test in schema.yml file for our clean_client model, we also apply dbt native data tests like unique and not_null to other columns:
models:
- name: clean_client
description: "Cleaned table for client data with technical and functional quality checks"
columns:
- name: client_id
description: "The primary key for this table"
data_tests:
- unique
- not_null
- name: client_name
description: "The name of the client"
data_tests:
- not_null
- name_format:
column_name: client_name
- name: date
description: "The date the client joined"
data_tests:
- not_null
- date_format:
column_name: dateWith these tests, dbt will ensure that client_id is unique, client_name is not null and follows the specified format, and the date is valid.
Incremental models
For larger data sets, it is inefficient to rebuild the tables from scratch. Instead, dbt supports incremental modelswhich only update new or changed data. Here is an example of how to set up an incremental model for our customer data:
{{ config(
materialized='incremental',
table_type='iceberg',
incremental_strategy='merge',
unique_key='client_id',
update_condition='target.client_name != src.client_name AND src.date > target.date',
format='parquet'
) }}
SELECT
client_id,
client_name,
date
FROM
{{ ref('client_data') }}This template only updates rows where the customer name has changed and the date is newer, ensure efficient and accurate data updates.
In summary, dbt makes data transformation faster and more reusable. By industrializing workflows, leveraging SQL macros, ensuring data quality and optimizing with incremental loading, it significantly improves the efficiency and reliability of transformation pipelines.
Section 2: Amazon Athena
Amazon Athena is a serverless interactive query service that simplifies querying data stored in S3.
With Athena, you can run SQL queries directly on data without needing to configure or manage infrastructure. It integrates perfectly with AWS services but is still too incomplete to effectively manage Lakehouse architectures, which is why a tool like dbt is so useful.
Advantages of Athena
Athena is profitable with its per-query pricing modelallowing you to pay only for the queries you run. It provides flexibility by querying data directly from S3, avoiding the need for data ingestion or transformation first.
Its scalability and ease of use make it a good choice for large-scale data analysis.
Integrate Athena with dbt
dbt can run transformations on Athena, leveraging SQL to efficiently manage and transform data. The dbt-Athena connector can materialize tables in in Iceberg or Hive formatand it supports incremental loading with these formats, allowing you to efficiently manage and update your data over time.
Additionally, the connector integrates with AWS Lake Formation to manage precise access control. It can apply Lake Formation tags and grants to table properties, ensuring detailed and secure access management based on your data needs.
This configuration makes Athena and dbt a powerful combination for managing and transforming data in a Lakehouse environment.
Section 3: Orchestrating dbt workflows with Dagster
Introduction to Dagster
Dagster is a open source data orchestration tool designed to manage and automate complex data flows.
It offers a powerful asset-oriented approach, where assets represent key components such as tables or datasets within a pipeline. This model allows us to detail management and monitoring of each step of the data transformation process.
Dagster also provides comprehensive scheduling, logging and monitoring tools, resolve some dbt Core limitationswhich lacks built-in orchestration and scheduling capabilities.
An example UI of a dbt pipeline in Dagster
Dagster multi-container architecture
Dagster’s architecture involves multiple containers, each with a distinct role:
- Web server container: hosts the Dagster web server, providing the user interface for managing and monitoring data pipelines.
- User code container: Contains dbt code and Dagster orchestration logic. It runs a gRPC server that interacts with both the web server and the daemon to perform tasks.
- Demon Container: Responsible for planning and launching tasks. It triggers new ECS tasks to run tasks in isolation when needed.
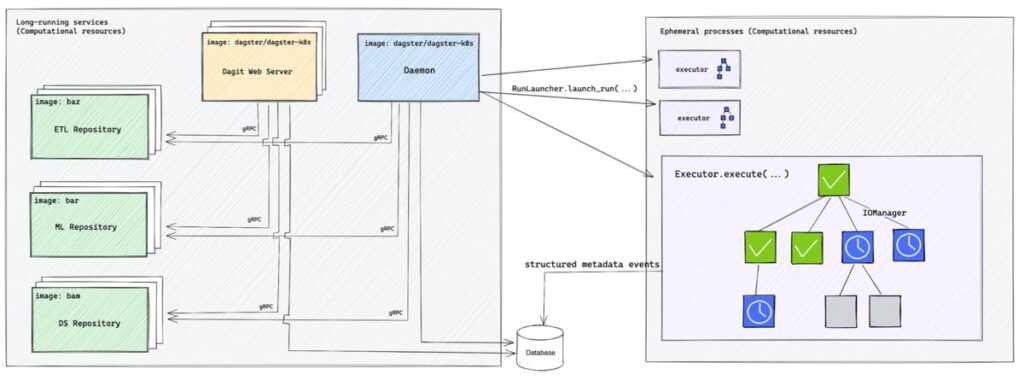
Representation of Dagster architecture
All three containers connect to a Postgres database, which manages execution storage, event logs, and scheduling. This separation of concerns allows for flexible management of your Dagster configuration. You can update and recontain user code independently, without disrupting the web server or daemon containers.
This modular approach makes it easy to iterate on dbt models and Dagster orchestration logic while maintaining the stability of your entire system.
Why Dagster to orchestrate the debt
Dagster improves dbt capabilities by manage data pipelines at the asset levelensuring that every table or dataset is tracked and monitored. It integrates seamlessly with dbt to run data quality checks and record the results during each transformation.
This integration ensures that you can supervise the entire pipeline, from data extraction to validation via a unified interface. Dagster’s ability to upload event logs to CloudWatch and its flexibility in configuring ECS task instances make it a solid choice for orchestrating dbt workflows within AWS.
Architecture and configuration of Dagster on AWS
To run Dagster on AWS, you will need several key resources:
- ECS Group: Hosts Dagster services.
- ECR Images: Container images for Dagster components (web server, scheduler and daemon).
- RDS Postgres Database: For storing Dagster applications.
- CloudWatch: To store and monitor dbt logs.
- Load Balancer: Gives access to the Dagster web server.
- VPC, security groups and subnets: Ensures secure and efficient communication between containers using private DNS.
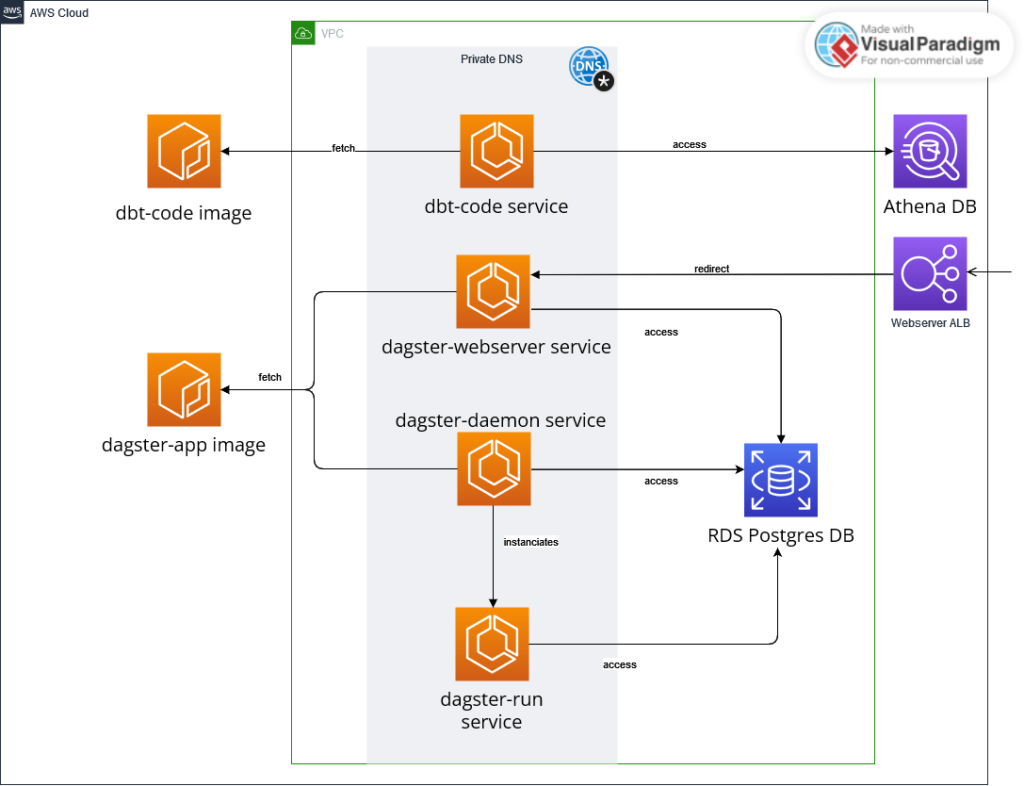
The deployment involves three ECS services, each running a single task, with containers pulling images from ECR. Configuration includes setting up private DNS for container-to-container communication, ensuring the correct security group and subnet settings are in place.
Conclusion
Using dbt core, Amazon Athena, and Dagster together creates a strong and efficient setup for managing data transformations and workflows. dbt core allows you to transform data using SQL and provides features such as incremental updates and data testing. Athena is a cost-effective serverless query engine that implements Well Lakehouse storage in Amazon S3. Dagster helps you manage and schedule your data tasks, filling in the gaps where dbt-core lacks built-in automation.
However, there are certain limitations to take into account. The dbt-Athena adapter does not support all dbt features and only works with certain table types (Iceberg or Hive).
Additionally, while Athena is powerful for querying data stored in S3, it may not be the best choice for every type of workload, especially those requiring real-time processing or low-speed responses. latency.
Dagster, while offering extensive orchestration capabilities, can add complexity to your setup and requires careful management of resources and dependencies.
The proof of concept (POC) we discussed shows how these tools can be put together to efficiently manage data transformations and workflows. It provides a practical example of using dbt for transformations, Athena for queries, and Dagster for orchestration. This POC demonstrates the potential of this stack but also highlights areas where further improvement and customization may be needed.
I’ll let you check for yourself here:
The next step is to take this POC and extend it into a complete ETL solution. This means increasing configuration, adding CI/CD automation for seamless updates, and refining the process to handle more complex data needs. The goal is to create a comprehensive, automated data system that can grow with your needs.